
Introducing BlindChat Local: Full In-Browser Confidential AI Assistant
Discover BlindChat, an open-source privacy-focused conversational AI that runs in your web browser, safeguarding your data while offering a seamless AI experience. Explore how it empowers users to enjoy both privacy and convenience in this transformative AI solution.
Key takeaways :
In this article, we introduce BlindChat Local, a private AI assistant. It's a privacy-by-design open-source tool.
- BlindChat Local, derived from HuggingFace’s Chat-UI, offers a local inference mode that shifts all processing to the client side, eliminating the need to send data server-side.
- BlindChat Local operates entirely in your browser, using transformers.js for local inference and saving conversations in the browser cache.
- The initial local model is LaMini-Flan-T5-783M
- We will soon release the BlindChat enclave option for private remote inference, with planned models including Phind-CodeLlama-34b.
You can try BlindChat Local yourself at chat.mithrilsecurity.io!
Context
The problem
Although OpenAI’s ChatGPT has reshaped the AI landscape, serious privacy concerns have emerged, which may hinder AI adoption.
We've witnessed significant productivity gains, thanks to LLMs, in tasks such as code completion and document creation. However, as a user, navigating the different privacy policies and understanding how AI providers handle data can be a challenge.
In order to improve Chatbots, AI providers often use the data sent to fine-tune their models. While this may boost models’ performance, this practice puts end users’ data at risk and can erode trust in these AI providers.
Several issues arise:
- Lack of clear, user-friendly data handling information: AI providers collect a lot of information, but it's often unclear what they collect, why, who they share it with, what they do with it, and how you can choose not to participate.
- Fine-tuning user data can lead to inadvertent data leakage: LLMs have the ability to inadvertently disclose this learned data to other users of the model. As you may be aware, LLMs are trained to memorize their training data, which means someone could inadvertently trigger the model to reveal portions or even the entirety of its training data. For example, using the prompt 'My credit card number is...' could result in the LLM generating a real credit card number from its training data.
In 2022, Samsung experienced an inadvertent data leak firsthand. One of their engineers unintentionally shared sensitive corporate information, including proprietary code, when using an early version of ChatGPT. While OpenAI does state that data sent to ChatGPT is logged and may be used for training, this engineer sent confidential company IP to GPT3.5, which resulted in the model memorizing the data shared and outputting it to another user.
Current solutions
On-premise deployment, where AI is deployed on the end user’s infrastructure, serves as the current choice for ensuring privacy and transparency in data usage: data is not sent to the AI provider, and thus can’t be accessed or used for fine-tuning. Open-source models like Llama 2 empower privacy-conscious developers to deploy their own LLMs internally, free from concerns of unregulated data handling. Commercial AI providers’ solutions may also offer similar deployment possibilities, such as Azure OpenAI Services.
While on-premise deployment addresses privacy and transparency concerns associated with using AI APIs like GPT4, they entail certain drawbacks: they can be expensive and require expertise to deploy. Deploying an LLM on-premise can be complex, especially for non-technical individuals! For example, a lawyer might seek a Chat solution for contract drafting but lack the technical proficiency to implement an in-house LLM.
This creates a dilemma, a tradeoff between privacy and ease of use and set-up. While Software as a Service (SaaS) solutions like GPT4 offer a smooth, user-friendly experience, they compromise on privacy compared to on-premise deployments, which require technical expertise.
However, we believe there is a solution that can bridge this gap effectively. That's precisely our goal with BlindChat Local, an open-source, in-browser Conversational AI that ensures both privacy and ease of use.
Introducing BlindChat Local
BlindChat Local is an open-source project that builds on HuggingFace’s Chat-UI and provides private inference. With our local inference mode, we move the server-side logic client side.
Our goal with BlindChat Local was to create a solution that operates exclusively within the browser, ensuring that end users can access AI models with the dual benefits of privacy and user-friendliness. This helps us meet two key objectives:
- provide privacy guarantees by ensuring that user data remains confined to the user's own device.
- provide ease of use: consumers don't need to install or set up anything. The only requirement is a browser! (Although BlindChat Local does require adequate bandwidth and hardware)
To achieve this goal, we ensured that:
- The LLM no longer operates on a distant server; instead, we use transformers.js to enable inference to take place directly on the user's device.
- Conversations are securely stored within the browser, eliminating reliance on remote servers.
- There's no longer any collection of telemetry data or data sharing for model improvement.
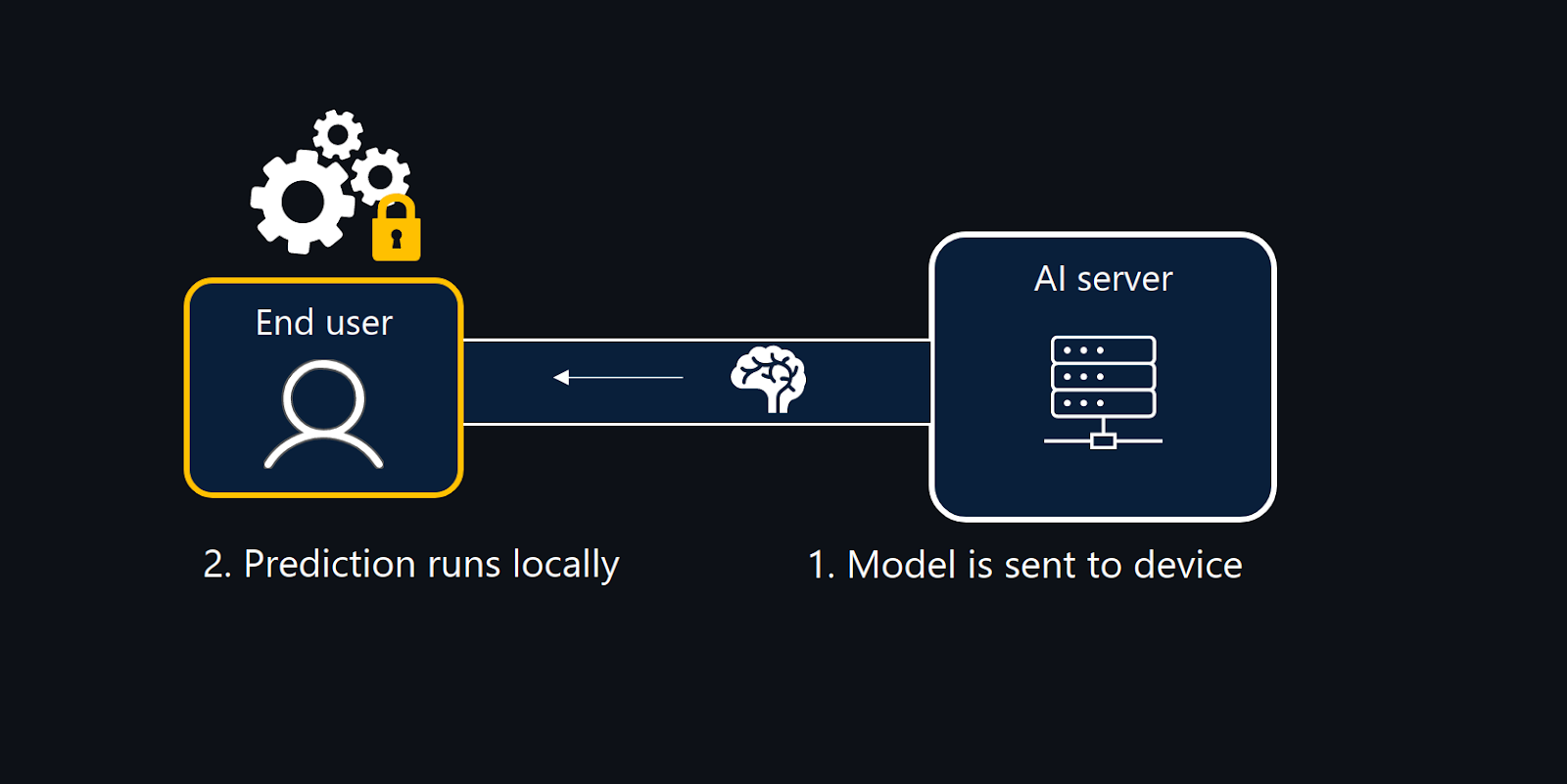
For example, with our current release, we offer local inference with LaMini-Flan-T5-783M. The model is downloaded and then executed directly on the user’s device. To enhance privacy, we also made adjustments to Chat-UI, ensuring that conversations are stored locally within the user's browser, rather than being stored on a server-side MongoDB.
You can try BlindChat Local at https://chat.mithrilsecurity.io/ to explore our privacy-centric AI Assistant.
⚠️ Note: Please be aware that this may require a robust network connection and may take a little time for the initial inference.
Next steps
This initial release featuring a basic private chat within the browser is only the start of our journey. Our goal is to create an open-source, privacy-focused AI Assistant, and we recognize that there's a considerable path ahead.
Here are just a few of the future milestones we plan to achieve:
- Provide more local models, such as phi-1.5
- Implement RAG by modifying LlamaIndex's TypeScript to make it work fully in-browser.
- Release BlindChat (the non-local version), which offers remote enclave inference. This will enable the consumption of large AI models hosted remotely while offering privacy guarantees.
If you're interested, you can discover more details about our future milestones and current progress on our roadmap.
Additionally, feel free to get in touch with us on Discord to share your thoughts with us or ask any questions you might have!


{kind=link}